
ACES: Accelerating Sparse Matrix Multiplication with Adaptive Execution Flow and Concurrency-Aware Cache Optimizations
Published in The 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2024), 2024
Xiaoyang Lu, Boyu Long, Xiaoming Chen, Yinhe Han, Xian-He Sun
Background
As AI applications grow in complexity, they require hardware architectures capable of handling massive memory demands and complex computations. Efficient processing of sparse data structures, especially in sparse matrix operations, is essential in many AI and scientific computing tasks. However, traditional architectures often struggle with the data movement overhead and irregular memory access patterns inherent in these applications.

Design
The ACES accelerator addresses these challenges through a novel combination of adaptive execution flows and concurrency-aware memory optimizations, specifically designed for Sparse Matrix-Matrix Multiplication. By optimizing both dataflow and memory management, ACES enhances the performance of sparse computations in AI, allowing efficient processing of data-intensive workloads.
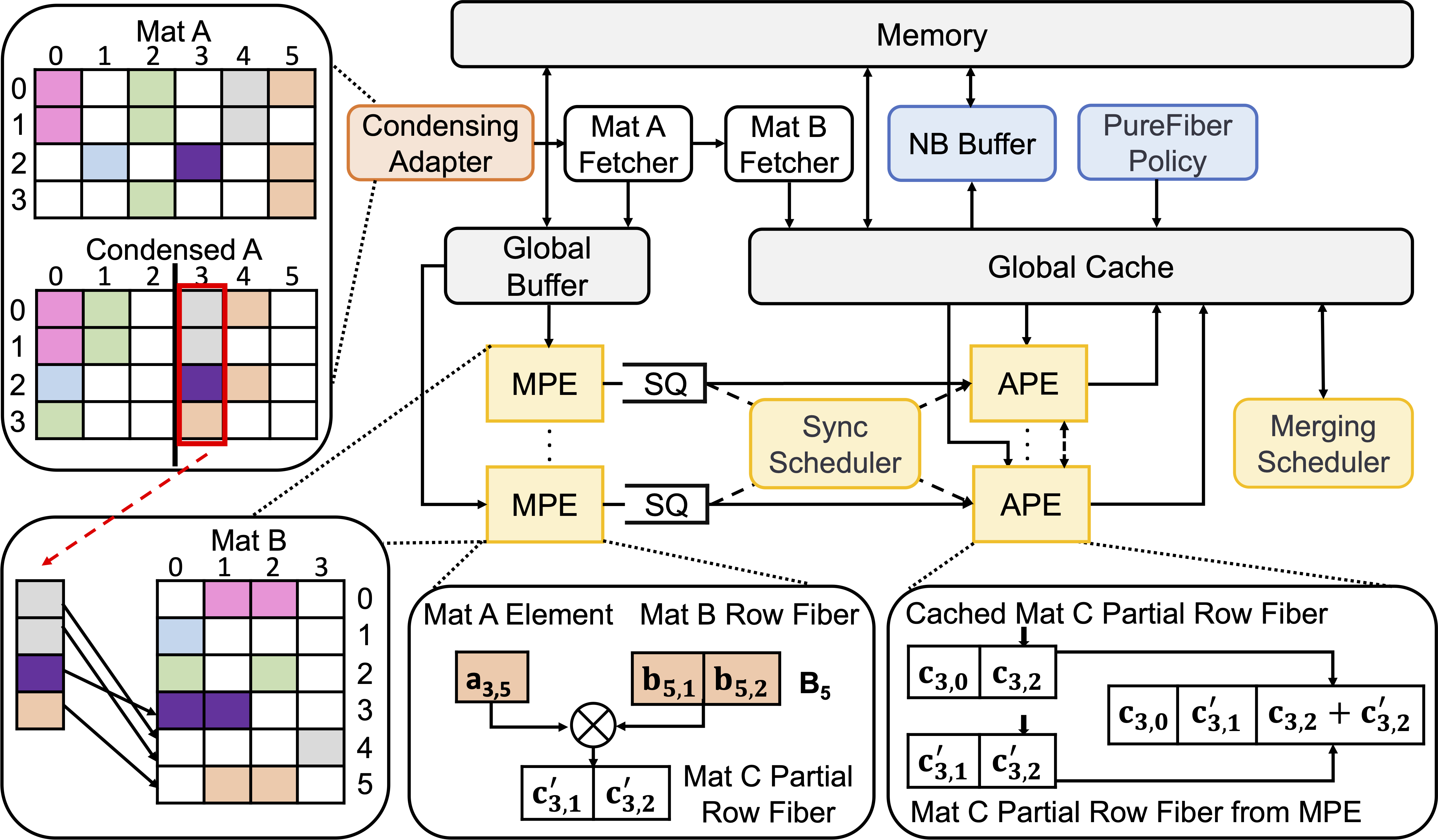
Overview of the ACES Accelerator Design
Key Features
- Adaptive Execution Flow: Dynamically adjusts execution flows based on input sparsity patterns to optimize parallelism and data reuse.
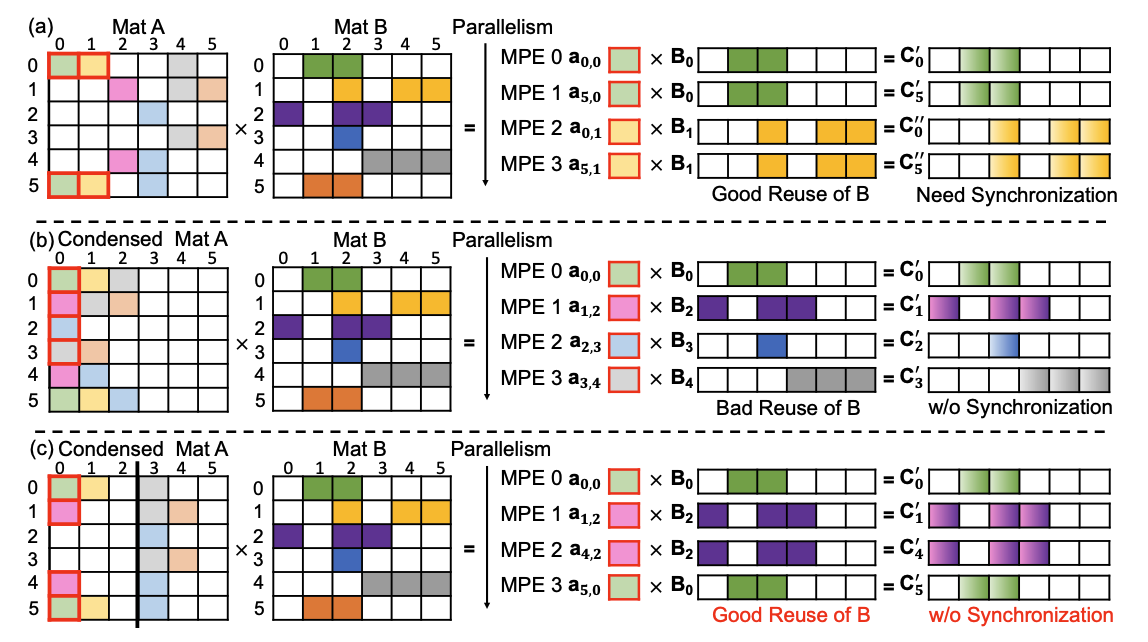
Three execution flows with different condensing degrees
- Balanced Data Reuse and Synchronization: Balances memory access with parallel execution to maximize data reuse and minimize synchronization overhead.
- Concurrency-Aware Cache Management: Employs the PureFiber cache replacement policy, considering reuse distance and concurrent accesses to improve cache performance.
- Non-Blocking Buffer Integration: Uses a non-blocking buffer to handle cache misses without stalling the pipeline, enhancing concurrency.
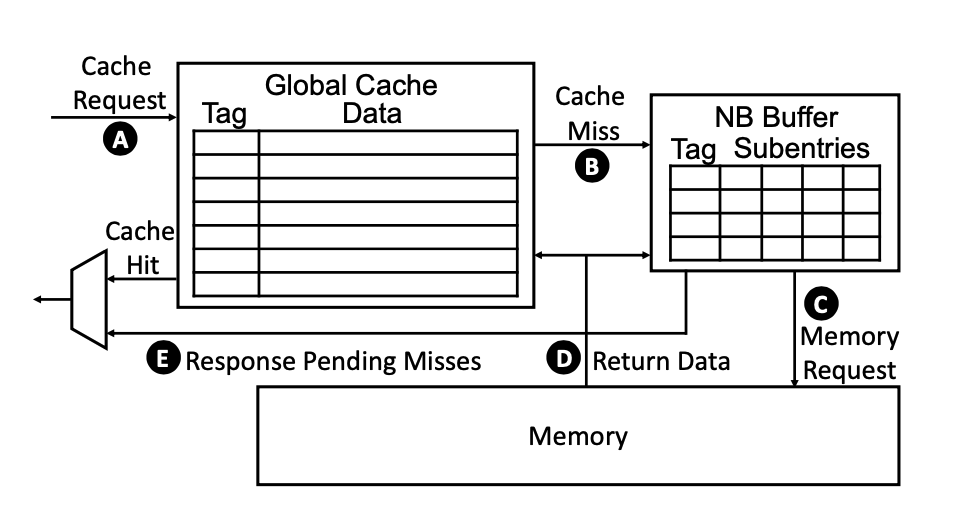
Organization of the non-blocking cache
Results
ACES achieves substantial improvements over traditional architectures, demonstrating significant performance gains in AI workloads that rely on sparse matrix computations. Experimental results show up to a 2.1× speedup.
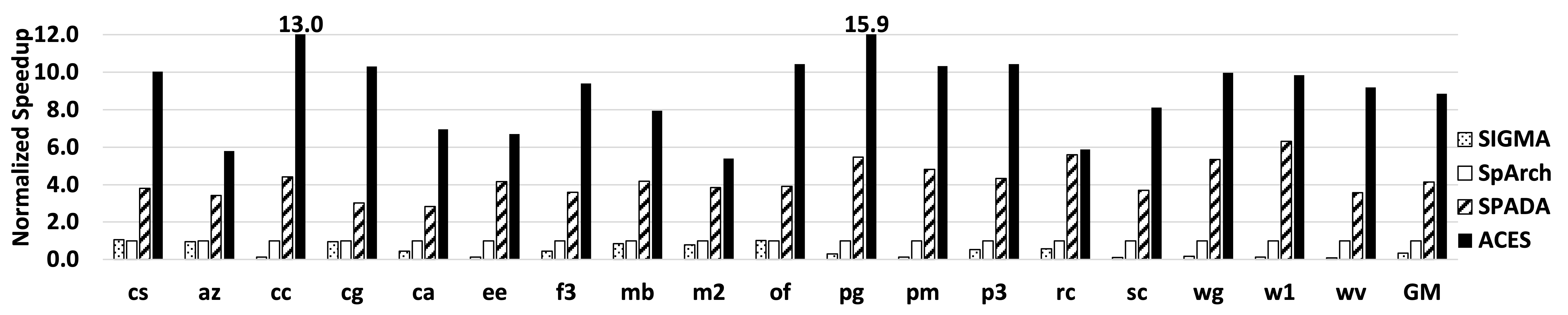
Performance comparison among SIGMA, SpArch, SPADA, and ACES
Conclusion
By integrating advanced dataflow and concurrency-aware memory optimizations, ACES provides a high-performance, scalable solution for handling the demands of modern AI applications. These innovations contribute to the overall efficiency and scalability of AI hardware, positioning ACES as a foundational component in the future of AI computing.